In this post we will learn about how to integrate Spring Batch with Quartz Scheduler to run batch job periodically. We will also see how to handle real world scenario where periodically, files are received dynamically (they may have different names on each run) in some input folder which can reside on file system (not necessarily the application classpath). We will see JobParameter usage to handle this scenario. We will also witness usage of Tasklet to archive file once they are processed. We will read (one or more) flat files (on each run) using FlatFileItemReader and write(append) all the records to a common output flat file using FlatFileItemWriter. Let’s get going.
- Spring Boot+AngularJS+Spring Data+Hibernate+MySQL CRUD App
- Spring Boot REST API Tutorial
- Spring Boot WAR deployment example
- Secure Spring REST API using OAuth2
- Spring Boot Introduction + Hello World Example
- AngularJS+Spring Security using Basic Authentication
- Secure Spring REST API using Basic Authentication
- Spring 4 Caching Annotations Tutorial
- Spring 4 Cache Tutorial with EhCache
- Spring 4 MVC+JPA2+Hibernate Many-to-many Example
- Spring 4 Email Template Library Example
- Spring 4 Email With Attachment Tutorial
- Spring 4 Email Integration Tutorial
- Spring MVC 4+JMS+ActiveMQ Integration Example
- Spring 4+JMS+ActiveMQ @JmsLister @EnableJms Example
- Spring 4+JMS+ActiveMQ Integration Example
- Spring MVC 4+Apache Tiles 3 Integration Example
- Spring MVC 4+Spring Security 4 + Hibernate Integration Example
- Spring MVC 4+AngularJS Example
- Spring MVC 4+AngularJS Routing with UI-Router Example
- Spring MVC 4 HelloWorld – Annotation/JavaConfig Example
- Spring MVC 4+Hibernate 4+MySQL+Maven integration example
- Spring 4 Hello World Example
- Spring Security 4 Hello World Annotation+XML Example
- Hibernate MySQL Maven Hello World Example (Annotation)
- TestNG Hello World Example
- JAXB2 Helloworld Example
- Spring Batch- Read a CSV file and write to an XML file
Following technologies being used:
- Spring Batch 3.0.1.RELEASE
- Spring core 4.0.6.RELEASE
- Quartz 2.2.1
- Joda Time 2.3
- JDK 1.6
- Eclipse JUNO Service Release 2
Let’s begin.
Step 1: Create project directory structure
Following will be the final project structure:
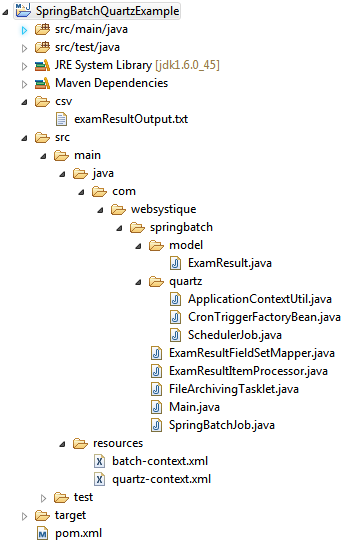
We will be reading the dynamic flat files from directory on file system (E:/inputFiles) and writing/appending the result of each run to output flat file (project/csv/examResultOutput.txt)
Now let’s add all contents mentioned in above figure.
Step 2: Update pom.xml to include required dependencies
Following is the updated minimalistic pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.websystique.springbatch</groupId>
<artifactId>SpringBatchQuartzExample</artifactId>
<version>1.0.0</version>
<packaging>jar</packaging>
<name>SpringBatchQuartzExample</name>
<properties>
<springframework.version>4.0.6.RELEASE</springframework.version>
<springbatch.version>3.0.1.RELEASE</springbatch.version>
<joda-time.version>2.3</joda-time.version>
<quartz.version>2.2.1</quartz.version>
<commons-io.version>2.4</commons-io.version>
</properties>
<dependencies>
<!-- Spring Core -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-core</artifactId>
<version>${springframework.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context-support</artifactId>
<version>${springframework.version}</version>
</dependency>
<!-- Spring Batch -->
<dependency>
<groupId>org.springframework.batch</groupId>
<artifactId>spring-batch-core</artifactId>
<version>${springbatch.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.batch</groupId>
<artifactId>spring-batch-infrastructure</artifactId>
<version>${springbatch.version}</version>
</dependency>
<!-- Quartz framework -->
<dependency>
<groupId>org.quartz-scheduler</groupId>
<artifactId>quartz</artifactId>
<version>${quartz.version}</version>
</dependency>
<!-- Joda-Time -->
<dependency>
<groupId>joda-time</groupId>
<artifactId>joda-time</artifactId>
<version>${joda-time.version}</version>
</dependency>
<!-- commons-io -->
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>${commons-io.version}</version>
</dependency>
</dependencies>
<build>
<pluginManagement>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.2</version>
<configuration>
<source>1.6</source>
<target>1.6</target>
</configuration>
</plugin>
</plugins>
</pluginManagement>
</build>
</project>
Step 3: Prepare the input flat files and corresponding domain object / mapped POJO
Below are the input files with ‘|’ separated fields which we will be putting (one or more) on each run in our input folder on file system (E:/inputFiles).
infile.txt
Shaun Pollack | 10/03/1975 | 85 Lance Klusner | 10/03/1972 | 98 Alan Donald | 01/02/1973 | 76
anotherinfile.txt
Brian Lara | 09/11/1971 | 92 Malcom Marshall | 10/03/1964 | 96 Vivian Richards | 03/08/1960 | 88 Kurtley Ambrose | 03/08/1971 | 61
yetanother.bak
Adam Gilchrist | 09/11/1977 | 91 Steve Waugh | 10/03/1971 | 76 Shane Warne | 03/08/1972 | 56 Andrew Symonds | 03/08/1973 | 61
Each Record in above files represents name, date of birth and precentage.
Below is the mapped POJO with fields corresponding to the records content of above file:
com.websystiqye.springbatch.model.ExamResult
package com.websystique.springbatch.model;
import org.joda.time.LocalDate;
public class ExamResult {
private String studentName;
private LocalDate dob;
private double percentage;
public String getStudentName() {
return studentName;
}
public void setStudentName(String studentName) {
this.studentName = studentName;
}
public LocalDate getDob() {
return dob;
}
public void setDob(LocalDate dob) {
this.dob = dob;
}
public double getPercentage() {
return percentage;
}
public void setPercentage(double percentage) {
this.percentage = percentage;
}
@Override
public String toString() {
return "ExamResult [studentName=" + studentName + ", dob=" + dob + ", percentage=" + percentage + "]";
}
}
Step 4: Create a FieldSetMapper
FieldSetMapper is responsible for mapping each field form the input to a domain object
com.websystiqye.springbatch.ExamResultFieldSetMapper
package com.websystique.springbatch;
import org.joda.time.LocalDate;
import org.springframework.batch.item.file.mapping.FieldSetMapper;
import org.springframework.batch.item.file.transform.FieldSet;
import org.springframework.validation.BindException;
import com.websystique.springbatch.model.ExamResult;
public class ExamResultFieldSetMapper implements FieldSetMapper<ExamResult>{
@Override
public ExamResult mapFieldSet(FieldSet fieldSet) throws BindException {
ExamResult result = new ExamResult();
result.setStudentName(fieldSet.readString(0));
result.setDob(new LocalDate(fieldSet.readDate(1,"dd/MM/yyyy")));
result.setPercentage(fieldSet.readDouble(2));
return result;
}
}
Step 5: Create an ItemProcessor
ItemProcessor is Optional, and called after item read but before item write. It gives us the opportunity to perform a business logic on each item.In our case, for example, we will filter out all the records whose percentage is less than 75. So final result will only have records with percentage >= 75.
com.websystiqye.springbatch.ExamResultItemProcessor
package com.websystique.springbatch;
import org.springframework.batch.item.ItemProcessor;
import com.websystique.springbatch.model.ExamResult;
public class ExamResultItemProcessor implements ItemProcessor<ExamResult, ExamResult>{
@Override
public ExamResult process(ExamResult result) throws Exception {
System.out.println("Processing result :"+result);
/*
* Only return results which are more than 75%
*
*/
if(result.getPercentage() < 75){
return null;
}
return result;
}
}
Step 6: Create actual spring batch job
com.websystiqye.springbatch.SpringBatchJob
package com.websystique.springbatch;
import java.io.File;
import java.util.Date;
import java.util.HashMap;
import java.util.Map;
import org.springframework.batch.core.JobExecution;
import org.springframework.batch.core.JobExecutionException;
import org.springframework.batch.core.JobParameter;
import org.springframework.batch.core.JobParameters;
import org.springframework.batch.core.configuration.JobLocator;
import org.springframework.batch.core.launch.JobLauncher;
public class SpringBatchJob {
private String jobName;
private JobLocator jobLocator;
private JobLauncher jobLauncher;
private File contentDirectory;
private String directoryPath = "E:/inputFiles";
public void init(){
contentDirectory = new File(directoryPath);
}
boolean fileFound = false;
public void performJob() {
System.out.println("Starting ExamResult Job");
try{
if(contentDirectory== null || !contentDirectory.isDirectory()){
System.err.println("Input directory doesn't exist. Job ExamResult terminated");
}
fileFound = false;
for(File file : contentDirectory.listFiles()){
if(file.isFile()){
System.out.println("File found :"+file.getAbsolutePath());
fileFound = true;
JobParameter param = new JobParameter(file.getAbsolutePath());
Map<String, JobParameter> map = new HashMap<String, JobParameter>();
map.put("examResultInputFile", param);
map.put("date", new JobParameter(new Date()));
JobExecution result = jobLauncher.run(jobLocator.getJob(jobName), new JobParameters(map));
System.out.println("ExamResult Job completetion details : "+result.toString());
}
}
if(!fileFound){
System.out.println("No Input file found, Job terminated.");
}
} catch(JobExecutionException ex){
System.out.println("ExamResult Job halted with following excpetion :" + ex);
}
}
public void setJobName(String jobName) {
this.jobName = jobName;
}
public void setJobLocator(JobLocator jobLocator) {
this.jobLocator = jobLocator;
}
public void setJobLauncher(JobLauncher jobLauncher) {
this.jobLauncher = jobLauncher;
}
}
Above class contains actual spring batch job logic. Method performJob will be called by scheduler periodically. On each run, we check a specific input directory where input files can be found. If files are present, then we create a map containing the actual file name plus a date (to make it unique among job parameters), and pass this map as an input to JobParameters followed by launching the job using JobLauncher. This map we will be referring to in spring context to create a reference to actual file resource.
Step 7: Add a Tasklet to archive file once processed
com.websystique.springbatch.FileArchivingTasklet
package com.websystique.springbatch;
import java.io.File;
import java.io.IOException;
import java.text.SimpleDateFormat;
import java.util.Map;
import org.apache.commons.io.FileUtils;
import org.joda.time.DateTime;
import org.joda.time.DateTimeZone;
import org.springframework.batch.core.StepContribution;
import org.springframework.batch.core.scope.context.ChunkContext;
import org.springframework.batch.core.step.tasklet.Tasklet;
import org.springframework.batch.repeat.RepeatStatus;
public class FileArchivingTasklet implements Tasklet{
private File archiveDirectory;
private String archiveDirectoryPath = "E:/archivedFiles";
public void init(){
archiveDirectory = new File(archiveDirectoryPath);
}
@Override
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {
Map<String, Object> map = chunkContext.getStepContext().getJobParameters();
String fileName = (String) map.get("examResultInputFile");
archiveFile(fileName);
return RepeatStatus.FINISHED;
}
public void archiveFile(String fileName) throws IOException{
System.out.println("Archiving file: "+fileName);
File file = new File(fileName);
File targetFile = new File(archiveDirectory, file.getName() + getSuffix());
FileUtils.moveFile(file, targetFile);
}
public String getSuffix(){
return "_" + new SimpleDateFormat("yyyyMMddHHmmss").format(new DateTime(DateTimeZone.UTC).toDate());
}
}
Tasklet execute method is called once the STEP above it (in job) is completed successfully.In our case, once we have processed our input file, the file will be archived (moved to a different folder E:/archivedFiles with timestamp suffixed).Notice the usage of jobParameters to get the filename of file we processes in previous STEP.
Step 8: Add Quartz related classes
Add the Quartz Job bean.
com.websystique.springbatch.quartz.SchedulerJob
package com.websystique.springbatch.quartz;
import org.quartz.DisallowConcurrentExecution;
import org.quartz.JobExecutionContext;
import org.springframework.context.ApplicationContext;
import org.springframework.scheduling.quartz.QuartzJobBean;
import com.websystique.springbatch.SpringBatchJob;
@DisallowConcurrentExecution
public class SchedulerJob extends QuartzJobBean{
private String batchJob;
public void setBatchJob(String batchJob){
this.batchJob = batchJob;
}
@Override
protected void executeInternal(JobExecutionContext context){
ApplicationContext applicationContext = ApplicationContextUtil.getApplicationContext();
SpringBatchJob job = applicationContext.getBean(batchJob, SpringBatchJob.class);
System.out.println("Quartz job started: "+ job);
try{
job.performJob();
}catch(Exception exception){
System.out.println("Job "+ batchJob+" could not be executed : "+ exception.getMessage());
}
System.out.println("Quartz job end");
}
}
Quartz scheduler calls (on each scheduled run) executeInternal method of class implementing QuartzJobBean. In this method, We are simply calling performJob of our Spring batch job class we created in step6. But we need some way to tell Scheduler about how to find our spring batch job bean which will be declared as a bean in spring context. To do that, we have used an implementation of ApplicationContextAware.
com.websystique.springbatch.quartz.ApplicationContextUtil
package com.websystique.springbatch.quartz;
import org.springframework.beans.BeansException;
import org.springframework.context.ApplicationContext;
import org.springframework.context.ApplicationContextAware;
public class ApplicationContextUtil implements ApplicationContextAware{
private static ApplicationContextUtil instance;
private ApplicationContext applicationContext;
private static synchronized ApplicationContextUtil getInstance(){
if(instance == null){
instance = new ApplicationContextUtil();
}
return instance;
}
@Override
public void setApplicationContext(ApplicationContext applicationContext)
throws BeansException {
if(getInstance().applicationContext == null){
getInstance().applicationContext = applicationContext;
}
}
public static ApplicationContext getApplicationContext(){
return getInstance().applicationContext;
}
}
And finally, we also need to configure Quartz CRON trigger to specify when and with which periodicity the job should run.
com.websystique.springbatch.quartz.CronTriggerFactoryBean
package com.websystique.springbatch.quartz;
import org.quartz.CronScheduleBuilder;
import org.quartz.Trigger;
import org.quartz.TriggerBuilder;
import org.springframework.beans.factory.FactoryBean;
public class CronTriggerFactoryBean implements FactoryBean<Trigger>{
private final String jobName;
private final String cronExpression;
public CronTriggerFactoryBean(String jobName, String cronExpression){
this.jobName = jobName;
this.cronExpression = cronExpression;
}
@Override
public Trigger getObject() throws Exception {
return TriggerBuilder
.newTrigger()
.forJob(jobName, "DEFAULT")
.withIdentity(jobName+"Trigger", "DEFAULT")
.withSchedule(CronScheduleBuilder.cronSchedule(cronExpression))
.build();
}
@Override
public Class<?> getObjectType() {
return Trigger.class;
}
@Override
public boolean isSingleton() {
return false;
}
}
Step 9: Add Spring application context for Quartz and Spring Batch
batch-context.xml
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:batch="http://www.springframework.org/schema/batch" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch-3.0.xsd
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.0.xsd"
default-autowire="byName" default-init-method="init">
<!-- JobRepository and JobLauncher are configuration/setup classes -->
<bean id="jobRepository" class="org.springframework.batch.core.repository.support.MapJobRepositoryFactoryBean" />
<bean id="jobLauncher" class="org.springframework.batch.core.launch.support.SimpleJobLauncher">
<property name="jobRepository" ref="jobRepository" />
</bean>
<bean id="jobRegistry" class="org.springframework.batch.core.configuration.support.MapJobRegistry"/>
<!--
A BeanPostProcessor that registers Job beans with a JobRegistry.
-->
<bean class="org.springframework.batch.core.configuration.support.JobRegistryBeanPostProcessor">
<property name="jobRegistry" ref="jobRegistry"/>
</bean>
<!-- Thanks to this bean, you can now refer dynamic files in input folder whose names can be different on each run-->
<bean id="inputExamResultJobFile" class="org.springframework.core.io.FileSystemResource" scope="step">
<constructor-arg value="#{jobParameters[examResultInputFile]}"/>
</bean>
<!-- ItemReader reads a complete line one by one from input file -->
<bean id="flatFileItemReader" class="org.springframework.batch.item.file.FlatFileItemReader" scope="step">
<property name="resource" ref="inputExamResultJobFile" />
<property name="lineMapper">
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="fieldSetMapper">
<!-- Mapper which maps each individual items in a record to properties in POJO -->
<bean class="com.websystique.springbatch.ExamResultFieldSetMapper" />
</property>
<property name="lineTokenizer">
<!-- A tokenizer class to be used when items in input record are separated by specific characters -->
<bean class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer">
<property name="delimiter" value="|" />
</bean>
</property>
</bean>
</property>
</bean>
<!-- ItemWriter writes a line into output flat file -->
<bean id="flatFileItemWriter" class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step">
<property name="resource" value="file:csv/examResultOutput.txt" />
<property name="appendAllowed" value="true" />
<property name="lineAggregator">
<!-- An Aggregator which converts an object into delimited list of strings -->
<bean
class="org.springframework.batch.item.file.transform.DelimitedLineAggregator">
<property name="delimiter" value="|" />
<property name="fieldExtractor">
<!-- Extractor which returns the value of beans property through reflection -->
<bean
class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor">
<property name="names" value="studentName, percentage, dob" />
</bean>
</property>
</bean>
</property>
</bean>
<!-- Optional ItemProcessor to perform business logic/filtering on the input records -->
<bean id="itemProcessor" class="com.websystique.springbatch.ExamResultItemProcessor" />
<!-- Step will need a transaction manager -->
<bean id="transactionManager" class="org.springframework.batch.support.transaction.ResourcelessTransactionManager" />
<bean id="fileArchivingTasklet" class="com.websystique.springbatch.FileArchivingTasklet" />
<!-- Actual Job -->
<batch:job id="examResultBatchJob" restartable="true">
<batch:step id="processFiles" next="archiveFiles">
<batch:tasklet allow-start-if-complete="false" start-limit="1" transaction-manager="transactionManager">
<batch:chunk reader="flatFileItemReader" writer="flatFileItemWriter" processor="itemProcessor" commit-interval="10" />
</batch:tasklet>
</batch:step>
<batch:step id="archiveFiles">
<batch:tasklet ref="fileArchivingTasklet" />
</batch:step>
</batch:job>
</beans>
Most interesting peace of configuration in above file is:
<bean id="inputExamResultJobFile" class="org.springframework.core.io.FileSystemResource" scope="step">
<constructor-arg value="#{jobParameters[examResultInputFile]}"/>
</bean>
which uses jobParameters along with Spring expression language to refer to the file resource whose name was set (as jobParameter) in our batch job in step6. Note that you don’t find such flexibility with regular FlatFileItemReader or MultiResourceItemReader configuration (using file: or classpath: to refer to actual resource) which once refereed to a resource, can not recognize a new resource on next run.
Rest of configuration is pretty obvious. We have declared a FlatFileItemReader (whose resource property now refers to the bean ‘inputExamResultJobFile’ described above) to read input flat files, FlatFileItemWriter to write the records to a specific file.We have also added a Tasklet in our job which we use to archive the file once processed.
quartz-context.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.0.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-4.0.xsd"
default-autowire="byName" default-init-method="init">
<import resource="batch-context.xml" />
<bean id="applicationContextUtil" class="com.websystique.springbatch.quartz.ApplicationContextUtil" />
<bean id="springBatchJob" class="com.websystique.springbatch.SpringBatchJob">
<property name="jobName" value="examResultBatchJob" />
<property name="jobLocator" ref="jobRegistry" />
<property name="jobLauncher" ref="jobLauncher" />
</bean>
<bean name="taskJobDetail" class="org.springframework.scheduling.quartz.JobDetailFactoryBean">
<property name="jobClass" value="com.websystique.springbatch.quartz.SchedulerJob" />
<property name="jobDataMap">
<map>
<entry key="batchJob" value="springBatchJob" />
</map>
</property>
<property name="durability" value="true" />
</bean>
<!-- Run the job every 1 minute -->
<bean id="taskCronTrigger" class="com.websystique.springbatch.quartz.CronTriggerFactoryBean">
<constructor-arg index="0" value="taskJobDetail" />
<constructor-arg index="1" value="0 0/1 * * * ?" />
</bean>
<bean id="quartzSchedulerFactoryBean" class="org.springframework.scheduling.quartz.SchedulerFactoryBean">
<property name="jobDetails">
<list>
<ref bean="taskJobDetail" />
</list>
</property>
<property name="triggers">
<list>
<ref bean="taskCronTrigger" />
</list>
</property>
<property name="quartzProperties">
<props>
<prop key="org.quartz.jobStore.class">org.quartz.simpl.RAMJobStore</prop>
</props>
</property>
</bean>
</beans>
Above we have declared a SchedulerFactoryBean which schedules the configured jobs (via jobDetails property) for mentioned time/peiodicity (using triggers property). In this example, job will be run each minute. Rest is the declareation of beans we have created above. Please visit Quartz Documentation to learn more about Quartz schedular usage.
Step 10: Run Scheduler
com.websystique.springbatch.Main
package com.websystique.springbatch;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class Main {
@SuppressWarnings({ "unused", "resource" })
public static void main(String[] args) {
ApplicationContext context = new ClassPathXmlApplicationContext("quartz-context.xml");
}
}
Run above class as Java application.Above class will load the application context and as a result, will start the scheduler.Job will be run each minute.
Now let’s place files in input folder (E:/inputFiles). For first run, place infile.txt, nothing on second run, then both anotherinfile.txt & yetanotehr.bak on third run. Below is the output for this setup:
INFO: Starting Quartz Scheduler now
Quartz job started: com.websystique.springbatch.SpringBatchJob@50a649
Starting ExamResult Job
File found :E:\inputFiles\infile.txt
Aug 9, 2014 11:34:00 AM org.springframework.batch.core.launch.support.SimpleJobLauncher run
INFO: Job: [FlowJob: [name=examResultBatchJob]] launched with the following parameters: [{examResultInputFile=E:\inputFiles\infile.txt, date=1407576840013}]
Aug 9, 2014 11:34:00 AM org.springframework.batch.core.job.SimpleStepHandler handleStep
INFO: Executing step: [processFiles]
Processing result :ExamResult [studentName=Shaun Pollack, dob=1975-03-10, percentage=85.0]
Processing result :ExamResult [studentName=Lance Klusner, dob=1972-03-10, percentage=98.0]
Processing result :ExamResult [studentName=Alan Donald, dob=1973-02-01, percentage=76.0]
Aug 9, 2014 11:34:00 AM org.springframework.batch.core.job.SimpleStepHandler handleStep
INFO: Executing step: [archiveFiles]
Archiving file: E:\inputFiles\infile.txt
Aug 9, 2014 11:34:00 AM org.springframework.batch.core.launch.support.SimpleJobLauncher run
INFO: Job: [FlowJob: [name=examResultBatchJob]] completed with the following parameters: [{examResultInputFile=E:\inputFiles\infile.txt, date=1407576840013}] and the following status: [COMPLETED]
ExamResult Job completetion details : JobExecution: id=0, version=2, startTime=Sat Aug 09 11:34:00 CEST 2014, endTime=Sat Aug 09 11:34:00 CEST 2014, lastUpdated=Sat Aug 09 11:34:00 CEST 2014, status=COMPLETED, exitStatus=exitCode=COMPLETED;exitDescription=, job=[JobInstance: id=0, version=0, Job=[examResultBatchJob]], jobParameters=[{examResultInputFile=E:\inputFiles\infile.txt, date=1407576840013}]
Quartz job end
Quartz job started: com.websystique.springbatch.SpringBatchJob@50a649
Starting ExamResult Job
No Input file found, Job terminated.
Quartz job end
Quartz job started: com.websystique.springbatch.SpringBatchJob@50a649
Starting ExamResult Job
File found :E:\inputFiles\anotherinfile.txt
Aug 9, 2014 11:36:00 AM org.springframework.batch.core.launch.support.SimpleJobLauncher run
INFO: Job: [FlowJob: [name=examResultBatchJob]] launched with the following parameters: [{examResultInputFile=E:\inputFiles\anotherinfile.txt, date=1407576960002}]
Aug 9, 2014 11:36:00 AM org.springframework.batch.core.job.SimpleStepHandler handleStep
INFO: Executing step: [processFiles]
Processing result :ExamResult [studentName=Adam Gilchrist, dob=1977-11-09, percentage=91.0]
Processing result :ExamResult [studentName=Steve Waugh, dob=1971-03-10, percentage=76.0]
Processing result :ExamResult [studentName=Shane Warne, dob=1972-08-03, percentage=56.0]
Processing result :ExamResult [studentName=Andrew Symonds, dob=1973-08-03, percentage=61.0]
Aug 9, 2014 11:36:00 AM org.springframework.batch.core.job.SimpleStepHandler handleStep
INFO: Executing step: [archiveFiles]
Archiving file: E:\inputFiles\anotherinfile.txt
Aug 9, 2014 11:36:00 AM org.springframework.batch.core.launch.support.SimpleJobLauncher run
INFO: Job: [FlowJob: [name=examResultBatchJob]] completed with the following parameters: [{examResultInputFile=E:\inputFiles\anotherinfile.txt, date=1407576960002}] and the following status: [COMPLETED]
ExamResult Job completetion details : JobExecution: id=1, version=2, startTime=Sat Aug 09 11:36:00 CEST 2014, endTime=Sat Aug 09 11:36:00 CEST 2014, lastUpdated=Sat Aug 09 11:36:00 CEST 2014, status=COMPLETED, exitStatus=exitCode=COMPLETED;exitDescription=, job=[JobInstance: id=1, version=0, Job=[examResultBatchJob]], jobParameters=[{examResultInputFile=E:\inputFiles\anotherinfile.txt, date=1407576960002}]
File found :E:\inputFiles\yetanother.bak
Aug 9, 2014 11:36:00 AM org.springframework.batch.core.launch.support.SimpleJobLauncher run
INFO: Job: [FlowJob: [name=examResultBatchJob]] launched with the following parameters: [{examResultInputFile=E:\inputFiles\yetanother.bak, date=1407576960091}]
Aug 9, 2014 11:36:00 AM org.springframework.batch.core.job.SimpleStepHandler handleStep
INFO: Executing step: [processFiles]
Processing result :ExamResult [studentName=Brian Lara, dob=1971-11-09, percentage=92.0]
Processing result :ExamResult [studentName=Malcom Marshall, dob=1964-03-10, percentage=96.0]
Processing result :ExamResult [studentName=Vivian Richards, dob=1960-08-03, percentage=88.0]
Processing result :ExamResult [studentName=Kurtley Ambrose, dob=1971-08-03, percentage=61.0]
Aug 9, 2014 11:36:00 AM org.springframework.batch.core.job.SimpleStepHandler handleStep
INFO: Executing step: [archiveFiles]
Archiving file: E:\inputFiles\yetanother.bak
Aug 9, 2014 11:36:00 AM org.springframework.batch.core.launch.support.SimpleJobLauncher run
INFO: Job: [FlowJob: [name=examResultBatchJob]] completed with the following parameters: [{examResultInputFile=E:\inputFiles\yetanother.bak, date=1407576960091}] and the following status: [COMPLETED]
ExamResult Job completetion details : JobExecution: id=2, version=2, startTime=Sat Aug 09 11:36:00 CEST 2014, endTime=Sat Aug 09 11:36:00 CEST 2014, lastUpdated=Sat Aug 09 11:36:00 CEST 2014, status=COMPLETED, exitStatus=exitCode=COMPLETED;exitDescription=, job=[JobInstance: id=2, version=0, Job=[examResultBatchJob]], jobParameters=[{examResultInputFile=E:\inputFiles\yetanother.bak, date=1407576960091}]
Quartz job end
And the generated output file csv/examResultOutput.txt content is:
Shaun Pollack|85.0|1975-03-10 Lance Klusner|98.0|1972-03-10 Alan Donald|76.0|1973-02-01 Adam Gilchrist|91.0|1977-11-09 Steve Waugh|76.0|1971-03-10 Brian Lara|92.0|1971-11-09 Malcom Marshall|96.0|1964-03-10 Vivian Richards|88.0|1960-08-03
Note that records not meeting the 75 % criteria(thanks to ItemProcessor filtering) are missing.
Finally, check the archived folder E:/archivedFiles , you will find the archived files with processing timestamp suffixed.
That’s it.
Download Source Code
References
If you like tutorials on this site, why not take a step further and connect me on Facebook , Google Plus & Twitter as well? I would love to hear your thoughts on these articles, it will help improve further our learning process.